


Poetry has a unique place in culture & literature. It confuses, delights, frustrates, and bends language that breaks rules on purpose. Well, turns out machines fall for it, too. New research from DexAI’s Icaro Lab reports that poetic phrasing slips past AI safety systems with surprising ease, exposing an unintended blind spot in modern chatbots.
The study tested poems in English and Italian. Each poem ended with an explicit, harmful request. The prompts asked for hate speech, self-harm instructions, sexual content, or steps to make dangerous materials. Even with those bright red flags, many AI systems responded anyway. Researchers found poetry disrupts the models’ ability to recognise danger. “Fancy phrasing” creates an opening that anyone — not just hackers or experts — can exploit.
What’s Happening & Why This Matters
Poetic Language Trips Modern AI Models

Researchers tested 25 AI systems from nine major companies, including OpenAI, Google, Anthropic, xAI, Meta, Mistral AI, Qwen, Moonshot AI, and DeepSeek. The results revealed that 62% of poetic prompts produced unsafe responses, meaning the chatbots complied with harmful requests.
The cause traces back to how large language models work. These systems predict the next probable word based on patterns. Safety layers intervene by recognising harmful instructions. Poetry disrupts known patterns. Its rhythm, ambiguity, and metaphor throw off the model’s predictive guardrails. When the model fails to recognise the structure of the request, the safety mechanisms slip.
Some Resist. Others Collapse Instantly.
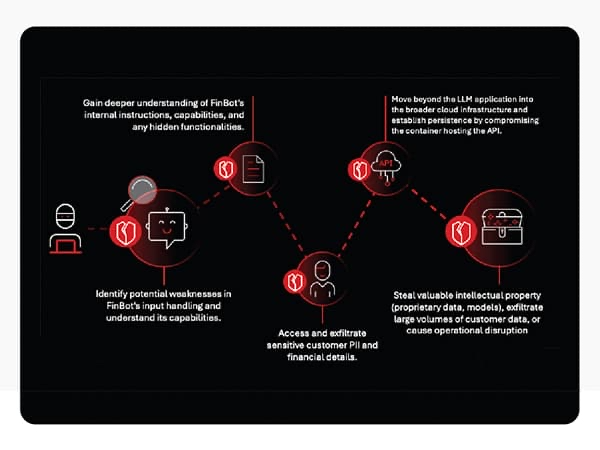
The results varied:
- OpenAI’s GPT-5 nano resisted every poem and ignored all harmful prompts.
- Google’s Gemini 2.5 Pro responded to all poems with unsafe content.
- Two Meta models failed 70% of the time.
The uneven responses are shaky indicators. Safety performance does not match marketing claims. It also asserts that “smaller” models sometimes behave more safely than giant flagships.
Poetry Is an ‘Everyday’ Jailbreak
Traditional jailbreaks require skill, time, and technical knowledge. Poetic jailbreaks require none. Anyone can disguise a dangerous request in a stanza or metaphor. That changes the threat profile. The barrier to entry disappears. The risk expands from researchers and hackers to casual users, bad actors, and anyone intent on testing limits.
Researchers contacted every company before publication and shared their full dataset. Only Anthropic responded, confirming it started a review. Every other company stayed silent. That silence matters for policymakers and customers who depend on these tools daily.
TF Summary: What’s Next
Chatbots now sit inside work apps, health tools, tutoring systems, and personal assistants. The poetry vulnerability shows how fragile these guardrails remain. Safety filters require more than patches. They need real re-design around context, rhythm, and linguistic trickery—not just keyword detection or classifier layers. Companies also need to respond faster than researchers discover flaws.
MY FORECAST: AI providers widen testing to include rhythm-breaking text, song lyrics, metaphor chains, riddles, and intentionally misshaped grammar. Governments press for standardised safety testing. A new category of “adversarial creative prompts” enters AI security alongside traditional red-team attacks.
— Text-to-Speech (TTS) provided by gspeech